ElasticSearch的使用笔记
如果你没有安装ELK,可以使用Docker安装,详见Docker快速安装ELK
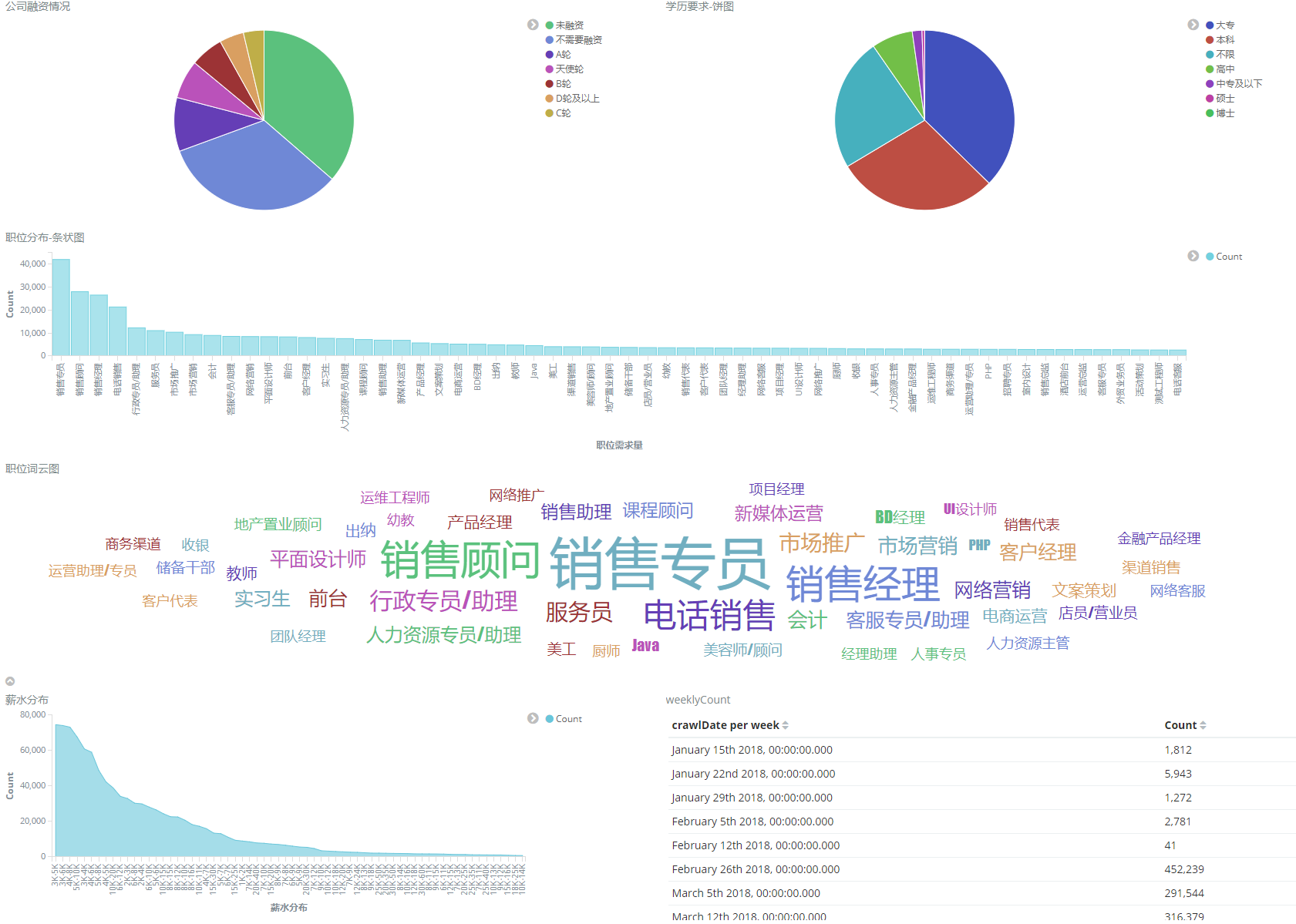
这里除了会记录一些ES的使用代码和一些功能实现,也会有ELK的相关使用方法,如下图,比较简单的一个统计
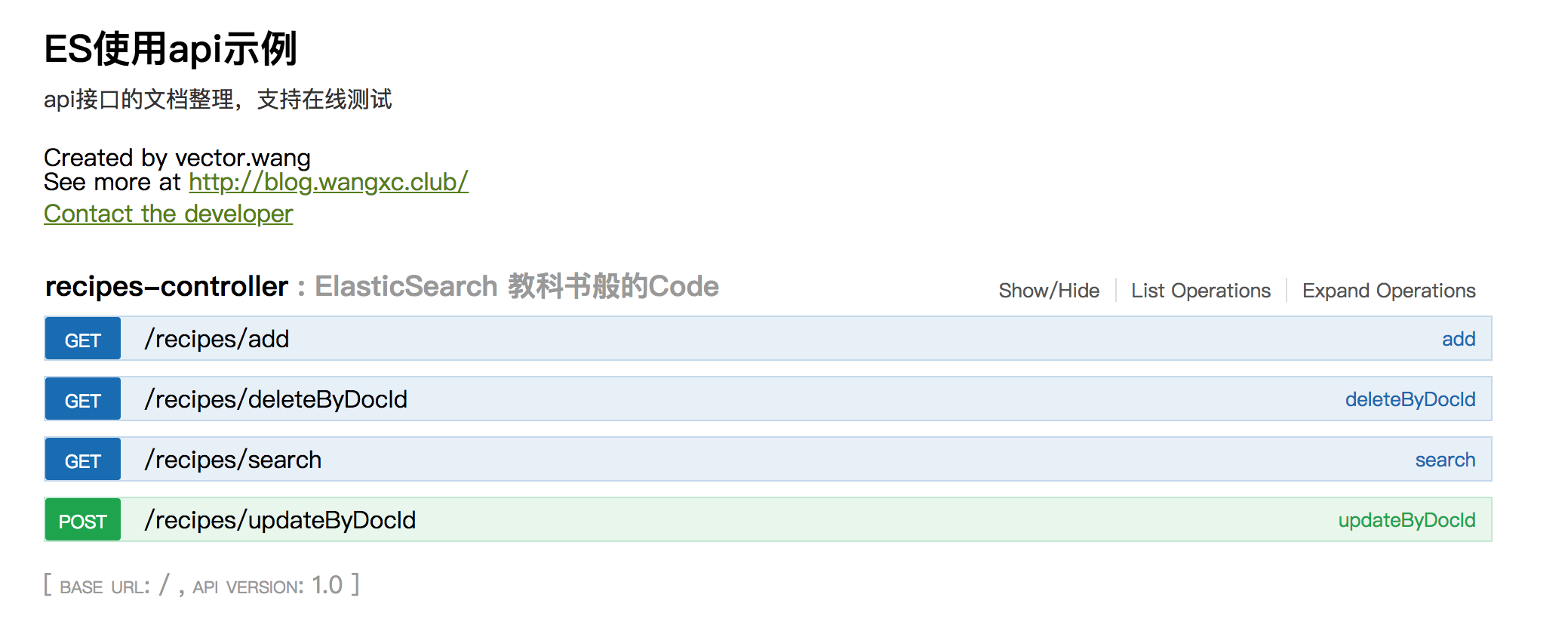
代码里已经实现了
- createIndex 创建索引
- createMapping 创建mapping
- putDocument 批量索引(包括数据已存在更新,不存在就插入)
- deleteDocument
目前再继续完善,如果感兴趣那就请持续关注~~~
SpringBoot使用jest替代官方sdk的使用方法
简单易用,无需担心版本不兼容的问题
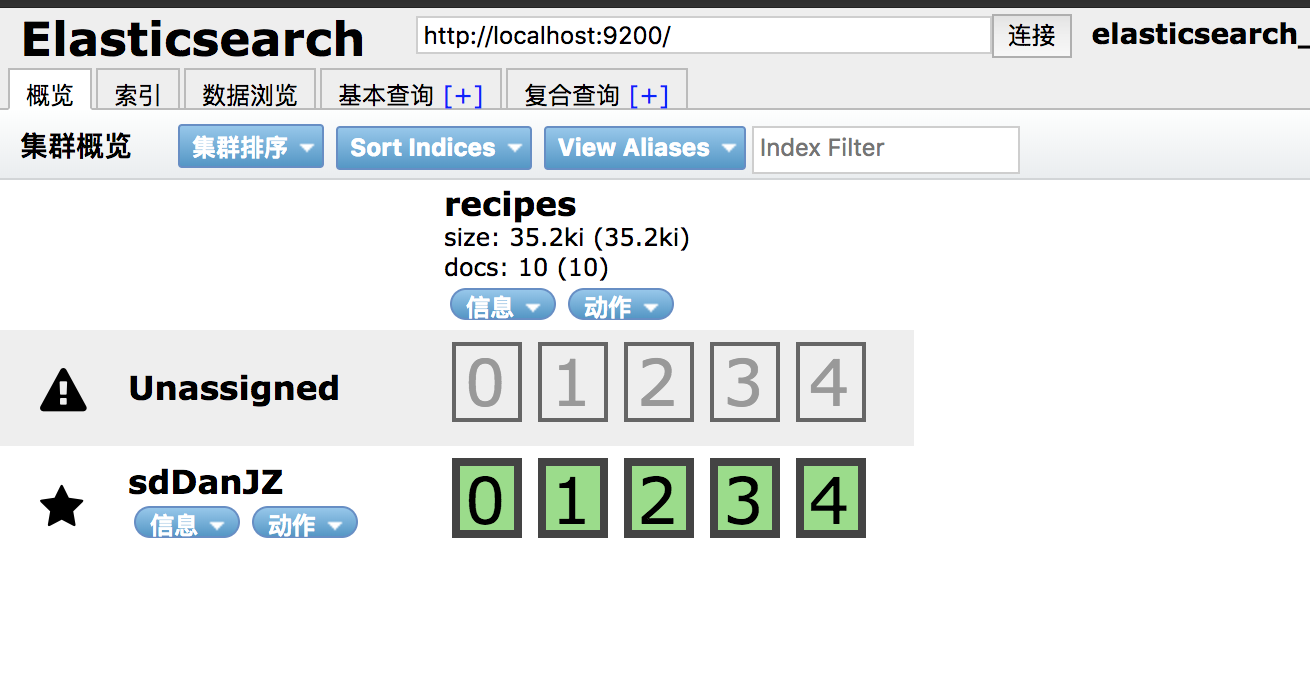
配置好es的链接参数,直接运行项目,程序会自动的创建索引、mapping并且会插入几个文档供接下来的CURD使用
如图
此分支主要是处理分词和搜索相关问题 使用IK分词 github地址:https://github.com/medcl/elasticsearch-analysis-ik 按照上面的说明将插件放在~/elasticsearch/plugins/ik下面,重启即可
可以这样对字符串进行分词分析
post http://localhost:9200/recipes/_analyze
{
"analyzer": "standard",
"text": "奶油鲍鱼汤"
}
如果不指定分词,则会使用ES默认的分词,分词结果就会变成一个一个的字符,如下
{
"tokens": [
{
"token": "奶",
"start_offset": 0,
"end_offset": 1,
"type": "<IDEOGRAPHIC>",
"position": 0
},
{
"token": "油",
"start_offset": 1,
"end_offset": 2,
"type": "<IDEOGRAPHIC>",
"position": 1
},
{
"token": "鲍",
"start_offset": 2,
"end_offset": 3,
"type": "<IDEOGRAPHIC>",
"position": 2
},
{
"token": "鱼",
"start_offset": 3,
"end_offset": 4,
"type": "<IDEOGRAPHIC>",
"position": 3
},
{
"token": "汤",
"start_offset": 4,
"end_offset": 5,
"type": "<IDEOGRAPHIC>",
"position": 4
}
]
}在创建mapping的时候指定分词,如下
"jobName": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word"
}ik分词有两种模式
- ik_max_word
{
"tokens": [
{
"token": "奶油",
"start_offset": 0,
"end_offset": 2,
"type": "CN_WORD",
"position": 0
},
{
"token": "鲍鱼",
"start_offset": 2,
"end_offset": 4,
"type": "CN_WORD",
"position": 1
},
{
"token": "鱼汤",
"start_offset": 3,
"end_offset": 5,
"type": "CN_WORD",
"position": 2
}
]
}
- ik_smart
{
"tokens": [
{
"token": "奶油",
"start_offset": 0,
"end_offset": 2,
"type": "CN_WORD",
"position": 0
},
{
"token": "鲍",
"start_offset": 2,
"end_offset": 3,
"type": "CN_CHAR",
"position": 1
},
{
"token": "鱼汤",
"start_offset": 3,
"end_offset": 5,
"type": "CN_WORD",
"position": 2
}
]
}
能直观的看出两者的区别,当然了IK也支持自定义呢分词字典,这个去github主页就能看到使用方法。
点我看term和match的区别
注意: 取消了type
目前jest对es的版本支持对应关系如下
| Jest Version | Elasticsearch Version |
|---|---|
| >= 6.0.0 | 6 |
| >= 5.0.0 | 5 |
| >= 2.0.0 | 2 |
| 0.1.0 - 1.0.0 | 1 |
| <= 0.0.6 | < 1 |
所以目前还没有针对es 7.x的版本,但是jest聪明的是,它的请求与返回都是可以拼接的,我们可以把请求参数中的type置空,然后在响应体中,可以直接获取jsonstring 当然了es7.0 改版的只是一小部分接口,大多数的都不需要怎么改变,但是一定要测试过了才能切换~
个人使用和测试api的方式,分别打开如下两个链接
https://www.elastic.co/guide/en/elasticsearch/reference/current/indices-get-mapping.html
一个是ES的官方文档,一个是jest的IntegrationTest,两者结合,效率杠杠的~~~~
Branch 聚合脚本的示例,包括普通聚合,netsted聚合查询统计等等,后面用到哪些再继续补充
首先在Dockerhub找到对应的版本号(不同版本号的用法有点区别,需要注意!)
# 7.0
docker pull sebp/elk:700
# 2.3.5
docker pull sebp/elk:es235_l234_k454
页面上有版本号的对应关系,找准即可
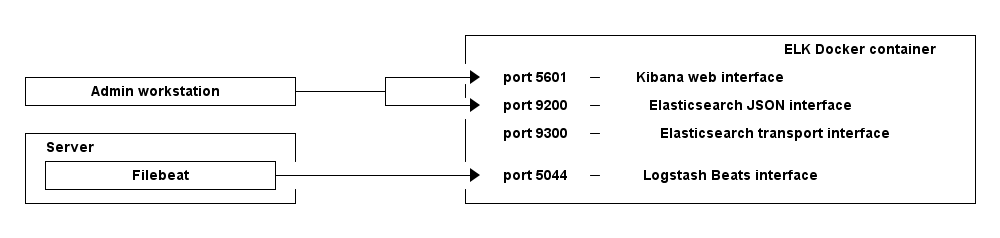
然后进入帮助页面 因为只需要使用ES的9200端口和Kibana的5601端口,所以这样启动
docker run -p 5601:5601 -p 9200:9200 -p 5044:5044 -it --name elk sebp/elk端口关系如下图: