A C++11 Serializer for High Performance Computing.

HPS is a header-only C++11 serialization library for serious high performance computing where we need to efficiently serialize and pass highly structured data over the network, write them to the file system, or compress them to reduce the memory consumption.
It is designed to be extremely easy to program and ultrafast for serializing common data structures in high performance computing, and with some amount of human efforts, it can also achieve optimal speed for heterogeneous data and handle backward data compatibility.
HPS is a header-only library.
Simply include the hps.h file, which includes all the other headers.
HPS is super easy to use. For primitive types and most STL containers, serialization requires only one line of code.
#include <cassert>
#include <iostream>
#include "../src/hps.h"
int main() {
std::vector<int> data({22, 333, -4444});
std::string serialized = hps::serialize_to_string(data);
auto parsed = hps::parse_from_string<std::vector<int>>(serialized);
assert(parsed == data);
std::cout << "size (B): " << serialized.size() << std::endl;
// size (B): 6
return 0;
}
// Compile with C++11 or above.Then we can send the string over the network in MPI for example
MPI_Send(serialized.c_str(), serialized.size(), MPI_CHAR, 0, 0, MPI_COMM_WORLD);There are also the serialize_to_stream and parse_from_stream functions for writing the data to or reading it from file streams.
The bottom of this document contains all the APIs that HPS provides.
We can also extend HPS to support custom types.
HPS internally uses static polymorphism on the class Serializer<DataType, BufferType> to support different types.
All we need to do is to specialize the Serializer for the new type, and HPS will support it, together with any combination of this type with STL containers and other specialized types.
The following example shows the serialization of a typical quantum system object consisting of several electrons, some of which are excited from orbitals orbs_from to orbs_to.
#include <cassert>
#include <iostream>
#include "../src/hps.h"
class QuantumState {
public:
uint16_t n_elecs;
std::unordered_set<uint16_t> orbs_from;
std::unordered_set<uint16_t> orbs_to;
};
namespace hps {
template <class B>
class Serializer<QuantumState, B> {
public:
static void serialize(const QuantumState& qs, OutputBuffer<B>& ob) {
Serializer<uint16_t, B>::serialize(qs.n_elecs, ob);
Serializer<std::unordered_set<uint16_t>, B>::serialize(qs.orbs_from, ob);
Serializer<std::unordered_set<uint16_t>, B>::serialize(qs.orbs_to, ob);
}
static void parse(QuantumState& qs, InputBuffer<B>& ib) {
Serializer<uint16_t, B>::parse(qs.n_elecs, ib);
Serializer<std::unordered_set<uint16_t>, B>::parse(qs.orbs_from, ib);
Serializer<std::unordered_set<uint16_t>, B>::parse(qs.orbs_to, ib);
}
};
} // namespace hps
int main() {
QuantumState qs;
qs.n_elecs = 33;
qs.orbs_from.insert({11, 22});
qs.orbs_to.insert({44, 66});
std::string serialized = hps::serialize_to_string(qs);
std::cout << "size (B): " << serialized.size() << std::endl;
// size (B): 7
return 0;
}
// Compile with C++11 or above.If needed, we can also leverage SFINAE to support multiple types with the same piece of code.
HPS makes extensive use of that internally.
See float_serializer.h for example.
The encoding scheme of HPS is very similar to Google's protobuf. Google provides an extremely detailed exlanation on that.
The major difference between protobuf's encoding scheme and HPS' is that the field numbers or wire types are not stored and the messages are always serialized and parsed in the same order unless explicitly specialized for custom types. This gives HPS a significant advantage in both the speed and the size of the serialized messages over protobuf on data with nested structures, especially when deeper structures are small.
Another difference is in the handling of the integral types.
There are no specific types for signed integers like the sint32 or sint64 in protobuf and the zigzag varint encoding will be used on standard int types, i.e. int, long long, etc.
And before serialization, we can use smaller integral types such as int16_t to store the data more compactly in memory constrained environments, instead of at least int32 as in protobuf.
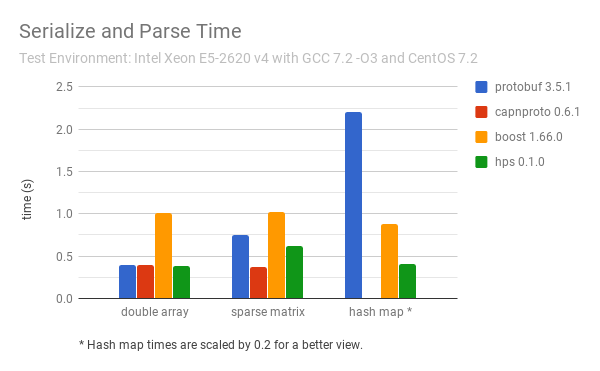
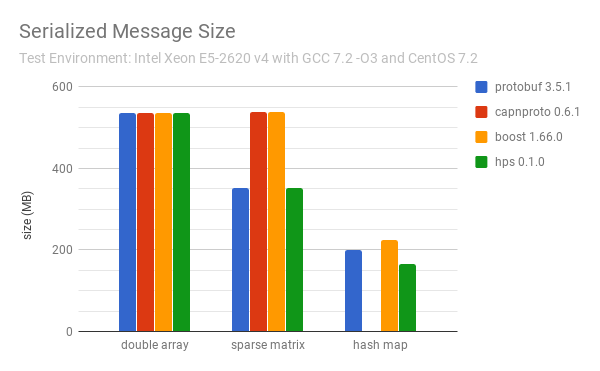
The performance of HPS comparing to other well-known C++ serializers for some most common data structures in high performance computing are as follows:
Note:
For the hash map benchmarks, both HPS and Boost serialize std::unordered_map directly, ProtoBuf uses its own Map type which may not be a hash map, and CapnProto does not support hash map or similar types at this time.
The test codes are in the benchmark directory.
// Serialize data t to an STL ostream.
void serialize_to_stream(const T& t, std::ostream& stream);// Parse from an STL istream and save to the data t passed in.
// Recommended for repeated use inside a loop.
void parse_from_stream(T& t, std::istream& stream);// Parse from an STL istream and return the data.
T parse_from_stream<T>(std::istream& stream);// Serialize data t to the STL string passed in.
// Recommended for repeated use inside a loop.
void serialize_to_string(const T& t, std::string& str);// Serialize data t to an STL string and return it.
std::string serialize_to_string(const T& t);// Parse from an STL string and save to the data t passed in.
// Recommended for repeated use inside a loop.
void parse_from_string(T& t, const std::string& str);// Parse from an STL string and return the data.
T parse_from_string<T>(const std::string& str);HPS supports the following types and any combinations of them out of the box:
- All primitive numeric types, e.g.
int, double, bool, char, uint8_t, size_t, ... - STL containers
string, array, deque, list, map, unordered_map, set, unordered_set, pair, vector.
Heterogeneous data here refer messages that contain data structures that occur repeatedly and have some fields in them missing irregularly in different instances of the structure.
There is no panacea for achieving the best performance for this type of data in all cases.
Protobuf uses an additional integer to indicate the existence of each field, which is best suitable for cases where there are lots of fields and most of them are missing.
Another possible encoding scheme is bit representation, i.e., use a bit vector to indicate the existence of the fields. This is best suitable for cases where there are not many fields and fields are missing less often.
And for cases where most of the fields seldom have missing values, the reverse of protobuf's scheme may be the best choice, i.e., use a vector to store the indices of the missing fields.